







AI and Large Language Models (LLMs), like ChatGPT, have become commonplace in our everyday lives and developments in the AI field keep coming at a steady pace. In this blog post, I will showcase a cutting-edge way to improve Retrieval Augmented Generation (RAG), using AWS and the LlamaIndex framework.
RAG recap
First, a quick recap of what RAG and context awareness mean. LLMs are trained on vast amounts of public data, making them aware of large amounts of different topics, but they are not aware of your data. This issue can be solved with RAG by making your data available to the LLM when generating responses. In practice, this means that the AI model you’re using is aware of the context your data provides without your data being used for training or fine-tuning the public model.
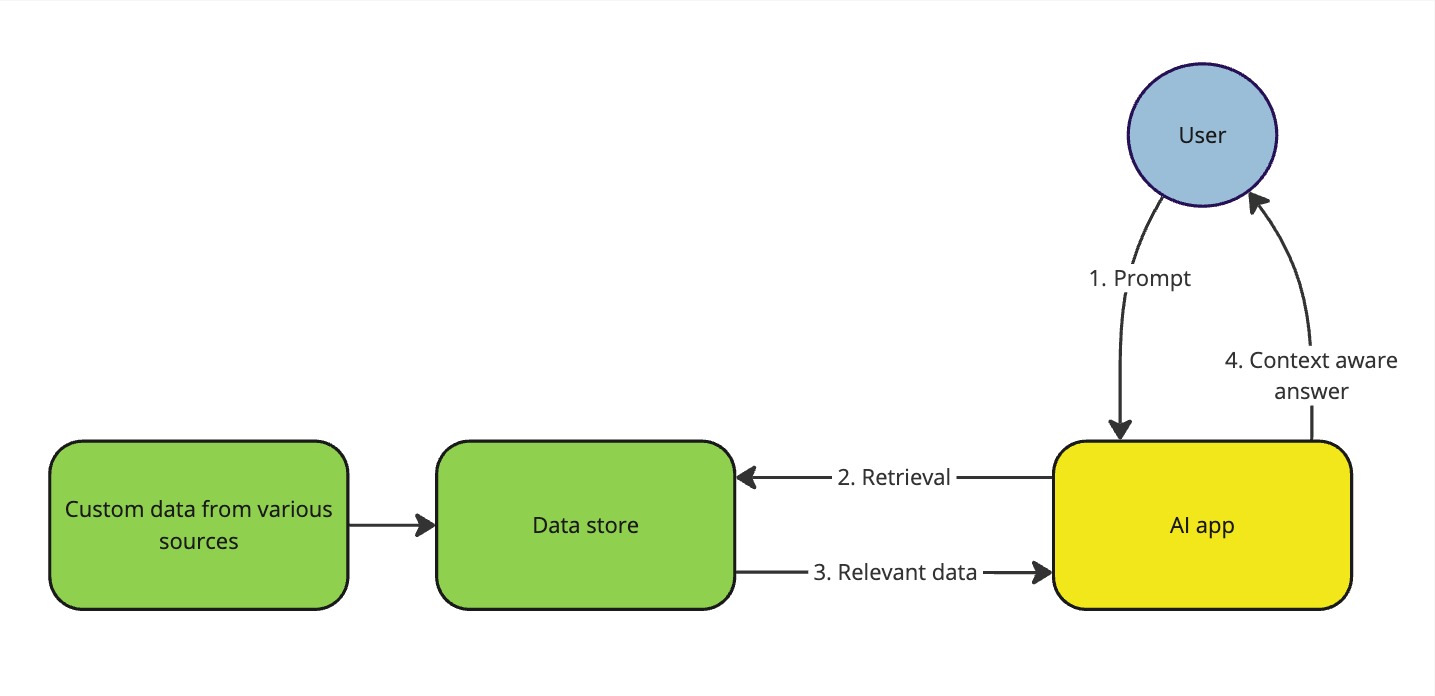
Simplified illustration of RAG
You also don’t have to train or fine-tune the underlying LLM with your data, when using RAG. This is a huge benefit since training LLMs is a long and costly endeavour. In the next section, I will introduce you to so-called “Graph RAG” i.e. RAG using a graph database, such as Neo4j or Amazon Neptune, as the source for the response context.
Advantages of using a graph database for RAG
Graph databases store nodes and relationships between the nodes instead of documents or tables. Think of a mind map drawn onto a whiteboard, that has information about relation between characters on a TV show. As an example, “Joey lives together with Chandler” would be represented in a graph database with Joey and Chandler being the nodes and “lives together with” as the relationship (or “edge”) between the nodes. The graph is built from data you provide and is called a “knowledge graph” or a “property graph”.
In the demo for this post, I used LlamaIndex which is an open source framework used for creating context aware generative AI applications. It offers tools for developing RAG capabilities both locally and on different cloud platforms. With LlamaIndex the data in the graph database is split into entities (nodes), relationships (edges) and chunks of text. When the user gives a prompt, the graph is traversed to find the path from the relevant nodes to the text chunks where they are mentioned. This is what Graph RAG is really about. Below is a partial visualisation of the graph database I created in my demo. I will use it as an example. All the chunks, nodes and edges have been created using AI, instead of modelling the data into a graph by hand.
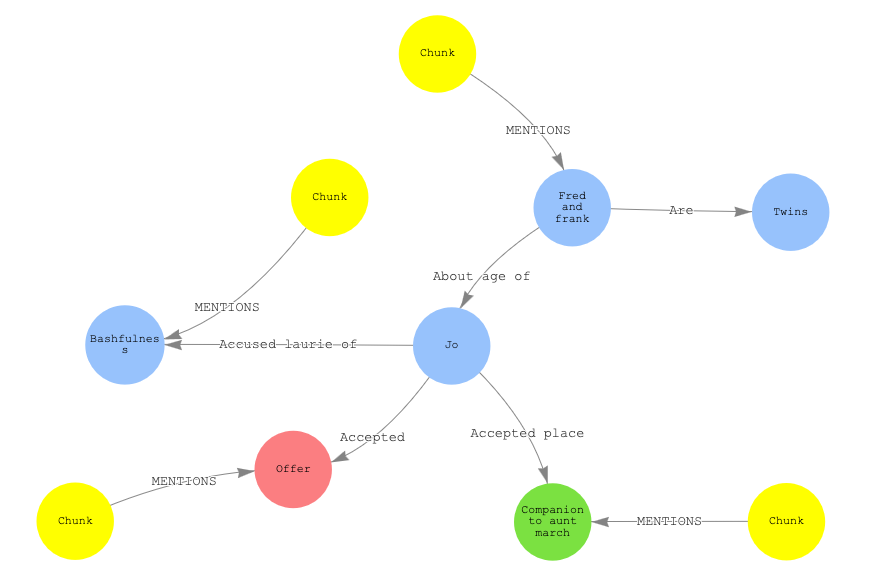
Small knowledge graph visualisation
Let’s say that the given prompt is “Tell me about Fred and Frank”. The graph can be traversed to find that they are twins and about the same age as Jo and also you can see what chunk of text is directly related to Fred and Frank. This is basically how Graph RAG works. Below is a visual representation of an openCypher query to find the neighbours and indirect neighbours of the node labelled “Jo”.

Large knowledge graph visualisation
The node in the centre is Jo, the blue nodes are text chunks related to Jo and the rest are other nodes that are either direct neighbours of the Jo-node or neighbours of Jo’s neighbours.
In my demo’s graph database, there are over 2 000 nodes and 5 000 edges between the nodes.
How can this be used with generative AI? RAG with a graph database, or Graph RAG, gives more structure and hierarchy to the context used for generating answers, when compared using just the text snippets. RAG without a graph database will be referred to as “Vector RAG” in this blog post. Under the hood, Vector RAG works by representing data as vectors and using them to retrieve relevant information for response generation. This is effective in finding how closely different words and phrases are related to each other. However, if you want to better understand the data that is represented or get a sense of how the data fits into a larger context, a knowledge graph is the key.
It’s important to note that Graph RAG does not remove the need for Vector RAG. Both vectors and graphs bring value to response generation and both are important in creating a good context aware generative AI application. In practice, the graph representation of data is bundled with the vectors when providing the context provided for the LLM responding to a user’s prompt.
The main advantage of Graph RAG is that, when implemented correctly, it provides more useful answers at a higher accuracy than Vector RAG. This is because plain Vector RAG is bad at “connecting the dots” between pieces of information. This is where the knowledge graph comes in handy.
Below is an example of two responses generated from the same prompt. The Vector RAG answer is generated using just vector embeddings from Amazon Bedrock knowledge base and the Graph RAG answer is generated with a knowledge graph in Amazon Neptune as the context. Both use Anthropic’s Claude 3 Sonnet LLM for generating the answer to the user’s prompt. Both have been given the book “Little Women” by Louisa May Alcott as the context.
Prompt: How did the March family react when Beth got sick?
Vector RAG response:
When Beth fell ill with scarlet fever in Little Women, the March family reacted with great concern and took immediate steps to care for her. Jo devoted herself to Beth day and night, while Meg stayed home to avoid infecting the Kings. Hannah, the servant, took charge of Beth’s care and called for Dr. Bangs to examine her. The family decided to send Amy away to Aunt March’s house to keep her safe from the illness. The family was deeply worried, especially when Beth began hallucinating during fever fits and did not recognize them. Meg wanted to write to Mrs. March about Beth’s illness against Hannah’s wishes. When a letter arrived saying Mr. March was gravely ill as well, the family was devastated, with Mrs. March resolving to go to him immediately despite the potential of being too late.
Graph RAG response:
Based on the context, when Beth fell seriously ill, the March family reacted with great concern and sadness. Some key details:
- Jo rushed out to send a telegram to summon their mother Mrs. March, as the doctor said Beth was very ill and Mrs. March should come home immediately.
- Meg dropped down in a chair, overwhelmed at the prospect of losing Beth. Jo was described as having a face “so full of misery.”
- When Beth didn’t recognize them and seemed close to death, Jo broke down crying and felt God seemed far away. Laurie comforted her.
- The sisters kept a vigil by Beth’s bedside, watching over her with a “dreadful sense of powerlessness.” They feared losing her, with Meg saying “If God spares Beth, I never will complain again.”
- When Beth seemed to rally, the doctor’s confirmation that the fever had turned was met with immense relief and joy by Jo and Meg, who crept away to rejoice with “hearts too full for words.”
So it was a time of profound worry, sadness and fear of loss for the March family, especially the sisters, until Beth’s condition finally improved.
In this example, we can see how much more detail was provided by the Graph RAG. Note that the Vector RAG answer has even given irrelevant information about Mr. March who does also get sick but this has happened in the book before Beth gets sick and the two cases are not related.
If you wish to learn more about Graph RAG, please see this blog post on the Neo4j website.
Graph RAG using Amazon Neptune and LlamaIndex
For this blog post, I’ve made a demonstration of Graph RAG using LlamaIndex and AWS services. The AWS services I mainly used for setting up the knowledge graph were S3 and Neptune. Amazon Neptune is a high-performance serverless graph database and recently has received support for LlamaIndex property graphs making it a viable platform for Graph RAG.
I started by creating a serverless Amazon Neptune cluster in a VPC on my dev sandbox AWS account. The cluster can be set up via CLI or infrastructure code, like Terraform or CDK, but I decided to use the AWS management console for the demo. Make sure to configure your VPC’s security groups, subnets and other networking options to allow traffic from your desired sources to the Neptune cluster on port 8182 (this is the default port used for connections to Neptune). To interact with the cluster I used a Jupyter notebook that I set up from the Neptune console. This actually starts a medium sized SageMaker instance in a subnet that has connectivity to the Neptune cluster. I uploaded my RAG material to S3 as a single text file.
LlamaIndex is used in this demo to create a property graph as it is called in their documentation, that holds information about different entities and their relationship in the given data. The property graph also includes “chunks” which are snippets of the actual data that are then given to the LLM used for generating the response. The LlamaIndex framework offers lots of different options and methods for creating and retrieving context for your generative AI applications and I highly recommend looking into it. What’s cool about LlamaIndex is that the framework uses user-specified LLMs during the process. I will showcase this later on.
Keep in mind though that the framework is open project and constantly being developed. Link to the documentation: https://docs.llamaindex.ai/en/stable/
In the Jupyter notebook, I used pip to install the required python packages:
%pip install boto3
%pip install s3fs
%pip install llama-index
%pip install llama-index-llms-bedrock
%pip install llama-index-graph-stores-neptune
%pip install llama-index-embeddings-bedrock
Then after importing required packages, I set the Neptune endpoint, configured the AI model’s I’d be using and then downloaded the material from S3
# If only reading from an existing graph then I recommend using the cluster's reader endpoint
# but if you're creating the knowledge graph, then use a writer instance endpoint
neptune_endpoint = "cluster-writer-instance.aws-region.neptune.amazonaws.com"
bucket_name = "bucket-name-here"
# Make sure to use model you have access to
llm_id = "anthropic.claude-3-sonnet-20240229-v1:0"
embed_model_id = "cohere.embed-english-v3"
# LLM is used for creating Neptune queries for retrieving context and generating responses to prompts
llm = Bedrock(model=llm_id, max_tokens=4096, temperature=0.0)
# Embedding model is used for creating vector embeddings that are also used in Graph RAG
embed_model = BedrockEmbedding(model=embed_model_id)
Settings.llm = llm
Settings.embed_model = embed_model
Settings.chunk_size = 1024
Settings.chunk_overlap = 50
# Data is read from S3
s3_fs = S3FileSystem(anon=False)
reader = SimpleDirectoryReader(
input_dir=bucket_name,
fs=s3_fs,
recursive=True
)
nest_asyncio.apply()
documents = await reader.aload_data()
After loading the documents, I recommend cleaning it up for better results. Here I’ve just removed newlines and trailing spaces. Also, I normalised whitespace around punctuation. Cleaning up your text is an important step in machine learning and a must-have in actual production data pipelines. Remember that with AI it is always “garbage in, garbage out”
import re
for document in documents:
document.text = re.sub(r'\s+', ' ', document.text).strip()
document.text = re.sub(r'\s+([?.!,])', r'\1', document.text)
The parts can be done in a variety of ways or by using the default settings. As an experiment, I’ve defined a lot of the LlamaIndex steps myself. The LlamaIndex framework does a lot of the work using LLMs like I stated before and I’ll showcase it in the following code blocks.
The basic workflow of the framework is that first the loaded documents are split into smaller snippets called “chunks”. This can be done with fixed chunk size or, as I’ve done in this demo, using an embeddings model to split the text into semantically similar chunks.
from llama_index.core.indices.property_graph import SimpleLLMPathExtractor, ImplicitPathExtractor
# Define the graph store. I'm using Amazon Neptune here
graph_store = NeptuneDatabasePropertyGraphStore(
host=neptune_endpoint,
port=8182
)
storage_context = StorageContext.from_defaults(graph_store=graph_store)
# The extractors in LlamaIndex are used to extract paths, also called triplets, from the text chunks.
# These paths are in the form: A -> RELATION -> B
# These are extracted by giving the chunks to an LLM of your choice
simple_kg_extractor = SimpleLLMPathExtractor(
llm=llm,
max_paths_per_chunk=20
)
implicit_kg_extractor = ImplicitPathExtractor()
# The property graph is created into Amazon Neptune using the extractor defined above
index = PropertyGraphIndex.from_documents(
documents,
storage_context=storage_context,
property_graph_store=graph_store,
embed_kg_nodes=False,
kg_extractors=[simple_kg_extractor, implicit_kg_extractor],
show_progress=True
)
Depending on the mass of your data, it might take a while for the property graph to be created. After the graph is created, it can be defined as an index and used to retrieve context for generating answers to user prompts. So called retrievers are used to get the context for response generation.
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.indices.property_graph import LLMSynonymRetriever, VectorContextRetriever
# I could also use an existing graph
# PropertyGraphIndex.from_existing(property_graph_store=graph_store)
# LLMSynonymRetriever uses an LLM to generate synonyms and keywords based on the prompt.
# These are then used to query paths in the property graph.
sub_retrievers = [
LLMSynonymRetriever(
index.property_graph_store,
llm=llm,
max_keywords=20,
path_depth=1,
include_text=True,
)
]
# Note that here the context is retrieved based on ONLY the graph database and not using vector embeddings also
query_engine = RetrieverQueryEngine.from_args(
index.as_retriever(sub_retrievers=sub_retrievers),
# Here I could add an postprocessing step to filter or rerank the retrieved chunks based on relevancy
)
response = query_engine.query("Have Jo and Laurie done something together?")
display(Markdown(f"<b>{response}</b>"))
Using the default methods and values is a great way to get started with LlamaIndex, so I’d recommend setting up the framework and trying it out for yourself. Note that you need to provide the framework access to the language and embedding models you’re using. I used the foundation models in Amazon Bedrock but a wide variety of different options are available, ranging from OpenAI’s Chat-GPT to anything found on Hugging Face.
The faithfulness and accuracy of the AI generated responses ultimately depends on a lot of variables. As with always when working with AI, the process needs a lot of fine-tuning, experimenting and quality data for getting good results. Since the methods and steps in LlamaIndex are very customizable, it really depends on the developer what they can achieve with the framework.
Here’s a couple more examples of the Graph RAG responses compared with Vector RAG:
Prompt: What happened between Meg and John Brooke?
Vector RAG response:
Meg and John Brooke got engaged. After Aunt March scolded Meg for defending John Brooke, Meg admitted to John that she cared for him. John then proposed to Meg and she accepted, whispering “Yes, John” and hiding her face on his waistcoat.The engagement caused a commotion in the family. Jo was upset and stormed off when she saw Meg and John together. The rest of the family seemed to be waiting for something to happen. Laurie acted out dramatically in the snow when he saw Meg, pretending to be heartbroken over her engagement to John.
Graph RAG response:
Based on the context, it seems that John Brooke proposed marriage to Meg, but she initially declined because she felt she was too young. However, after some persuasion from Aunt March (who wanted Meg to make a wealthy match), Meg accepted John’s proposal. There was some drama around Aunt March disapproving of Meg marrying someone poor like John Brooke, but ultimately Meg decided to go ahead and accept his proposal despite her aunt’s objections.
Here the Graph RAG response stays focussed on Meg and John Brooke specifically while the Vector RAG describes how Jo and Laurie react.
Prompt: Tell me about Jo’s book
Vector RAG response:
Jo wrote a book or story that she submitted to a newspaper for publication. She was very excited about it and kept it a secret from her sisters at first. However, Amy found out about the book and hid it from Jo, leading to a fight between them.Jo was very passionate about writing and had ambitions to do something “very splendid” with her writing. She would often sneak away to write in private, such as going up to the library or writing in her attic room.
Graph RAG response:
Jo’s book was a collection of little fairy tales that she had worked on patiently for several years, putting her whole heart into it. It was only half a dozen stories, but Jo had high hopes that it could be good enough to get published one day. She had just carefully recopied the manuscript after destroying the old one. Tragically, Amy burned Jo’s only copy of the book in a fit of anger, consuming years of Jo’s loving work. This was a devastating loss for Jo, as the book was the pride of her heart and regarded by her family as a literary work of great promise. Though it seemed a small thing to others, to Jo it was an unforgivable calamity that could never be made up.
In this example the Vector RAG response is simply incorrect. If you’re familiar with the story you know the response created with Graph RAG is what Jo’s book was and what happened to it.
Final thoughts
With new applications for generative AI coming out every month, it can feel a bit overwhelming to keep up and discern what’s worth your attention. Graph RAG truly feels like the next big thing in generative AI since it takes RAG to the next level and I’m excited to follow how this will be implemented and used in the near future. I hope that LlamaIndex will keep improving the support for AWS.
The development of this blog post’s demo was tricky since support for property graphs on Amazon Neptune has just recently come out and therefore examples are scarce. Also some available features really seemed to struggle with the amount of data I was using. LlamaIndex supports a feature that uses an LLM to generate openCypher queries for retrieving context from the graph database. When I tried to implement it, my connection to Neptune kept timing out or the generated Bedrock API call was way too large. These issues seemed to come from the fact that the openCypher queries and Bedrock API calls included a huge amount of nodes in the property graph. LlamaIndex documentation on Amazon Neptune is non-existent which really didn’t help my development process.
When implemented correctly, Graph RAG will bring a lot of value to generative AI applications by retrieving more structured context with better relevancy compared to plain Vector RAG that are based on vector embeddings only.
I hope this article has shed some light on the latest developments in generative AI and encouraged you to start building your own Graph RAG solutions. We here at NordHero have experience in building innovative Data and GenAI architectures and are ready to provide our expertise to you.
A huge thank you goes to GitHub user bechbd for implementing LlamaIndex property graph support on Amazon Neptune.